How to Update SCCM to Version 1902 – Quick Guide
How to update to SCCM 1902
Microsoft System Center Configuration Manager (SCCM) is a powerful tool used by organizations to manage their IT infrastructure. SCCM allows IT administrators to manage operating systems, applications, and updates on a large number of devices. With the release of SCCM 1902, Microsoft has added new features and improvements to the software. If you are using an older version of SCCM, it is important to update to SCCM 1902 to take advantage of these new features.
In this article, we will provide you with a step-by-step guide on how to update to SCCM 1902.
SCCM 1902 New Features
- Cloud Value
- Cloud Management Gateway (CMG) can be associated with boundary groups – Cloud Management Gateway deployments can now be associated with boundary groups to allow clients to default or fallback to the CMG for client communication according to boundary group relationships.
- Stop cloud service when it exceeds threshold – Configuration Manager can now stop a cloud management gateway (CMG) service when the total data transfer goes over your limit.
- Application Management
- Improvements to application approvals via email – When users request applications from Software Center, the email notification will now include their comments.
- Configuration Manager console
- Improvements to Configuration Manager console – Based on customer feedback aka the Cabana sessions at the Midwest Management Summit (MMS) Desert Edition 2018, this release includes several improvements to the Configuration Manager console.
- View recently connected consoles – You can now view the most recent connections for the Configuration Manager console. The view includes active connections and those that recently connected.
- View first monitor only during Configuration Manager remote control session – When connecting to a client with two or more monitors, a remote tools operator can now choose between seeing all monitors and the first monitor only.
- Search device views using MAC address – you can now search for a MAC address in a device view of the Configuration Manager console.
- Software Center
- Replace toast notifications with dialog window – When deployments need a restart or software changes are required, you now have the option of using a more intrusive dialog window to replace toast notifications on the client
- Configure default views in Software Center – You can now customize your end user’s default application layout and default application filter in Software Center.
- OS Deployment
- Improvements to task sequence media creation – When you create task sequence media, you can now customize the location that the site uses for temporary storage of data and add a label to the media.
- Improvements to Run PowerShell Script task sequence step – The Run PowerShell Script task sequence step now allows you to specify a timeout value, alternate credentials, a working directory and success codes.
- Import a single index of an Operating System Image – When importing a Windows image (WIM) file to Configuration Manager, you can now specify to automatically import a single index rather than all image indexes in the file.
- Progress status during in-place upgrade task sequence – You now see a more detailed progress bar during a Windows 10 in-place upgrade task sequence.
- Client Management
- Client Health Dashboard – You can now view a dashboard with information about the client health of your environment. View your client health, scenario health, common errors along with breakdowns by operating system and client versions.
- Specify a custom port for peer wakeup – You can now specify a custom port number for wake-up proxy.
- Real-time management
- Run CMPivot from the central administration site – Configuration Manager now supports running CMPivot from the central administration site in a hierarchy.
- Edit or copy PowerShell scripts – You can now Edit or Copy an existing PowerShell script used with the Run Scripts feature.
- Phased deployments
- Dedicated monitoring for phased deployments – Phased deployments now have their own dedicated monitoring node, making it easier to identify phased deployments you have created and navigate to the phased deployment monitoring view.
- Improvement to phased deployment success criteria – Specify additional criteria for the success of a phase in a phased deployment. Instead of only a percentage, these criteria can now also include the number of devices successfully deployed.
- Office Management
- Integration with analytics for Office 365 ProPlus readiness – Use Configuration Manager to identify devices with high confidence that are ready to upgrade to Office 365 ProPlus.
- Additional languages for Office 365 updates – Configuration Manager now supports all supported languages for Office 365 client updates.
- Office products on lifecycle dashboard – The product lifecycle dashboard now includes information for installed versions of Office 2003 through Office 2016.Redirect Windows known folders to OneDrive – Use Configuration Manager to move Windows known folders to OneDrive for Business. These folders include Desktop, Documents, and Pictures.
- OS servicing
- Optimized image servicing – When you apply software updates to an OS image, there’s a new option to optimize the output by removing any superseded updates.
- Specify thread priority for feature updates in Windows 10 servicing – Adjust the priority with which clients install a feature update through Windows 10 servicing.
Simplification - Management insight rules for collections – Management insights has new rules with recommendations on managing collections. Use these insights to simplify management and improve performance.
- Distribution Point Maintenance Mode – You can now set a distribution point in maintenance mode. Enable maintenance mode when you’re installing software updates or making hardware changes to the server.
- Configuration Manager Console Notifications – To keep you better informed so that you can take the appropriate action, the Configuration Manager console now notifies you when lifecycle and maintenance events occur in the environment.
- In-console documentation dashboard – There is a new Documentation node in the new Community workspace. This node includes up-to-date information about Configuration Manager documentation and support articles.
SCCM 1902 FAQs
| Question | Answer |
|---|---|
What is SCCM 1902? |
SCCM 1902 is the latest version of System Center Configuration Manager, released by Microsoft in March 2019. |
What are the new features in SCCM 1902? |
SCCM 1902 comes with several new features, including the ability to deploy Win32 applications using Intune, improved device compliance, and enhanced cloud management. |
What are the system requirements for SCCM 1902? |
Operating System Requirements
Hardware Requirements
Software Requirements
|
Can I upgrade to SCCM 1902 from an older version? |
Yes, you can upgrade to SCCM 1902 from an older version, but you need to follow the upgrade path and ensure that your infrastructure meets the prerequisites for the upgrade. |
How do I upgrade to SCCM 1902? |
You can upgrade to SCCM 1902 using the SCCM Console or command line, following a step-by-step process that includes downloading the update, running the prerequisite check, installing the update, and monitoring the progress. Follow the guide below showing the exact steps to perform the upgrade |
How long does it take to upgrade to SCCM 1902? |
The time required to upgrade to SCCM 1902 depends on the size and complexity of your SCCM infrastructure, but it typically takes a few hours to complete the upgrade process. |
What should I do after upgrading to SCCM 1902? |
After upgrading to SCCM 1902, you should verify that your infrastructure is running the latest version, review and update your configuration settings, and test your SCCM infrastructure to ensure that all components are working correctly. |
Where can I find more information about SCCM 1902? |
You can find more information about SCCM 1902 in the Microsoft documentation, including release notes, installation guides, and troubleshooting guides. |
SCCM 1902 Upgrade Process
Now, to upgrade to SCCM 1902 is quite an easy process, just follow these tasks below:
As with any upgrade or update, make sure you have an easy roll back position should anything cause an issue, either make sure you have a last known good backup or take a snapshot of your SCCM server prior to applying this update;
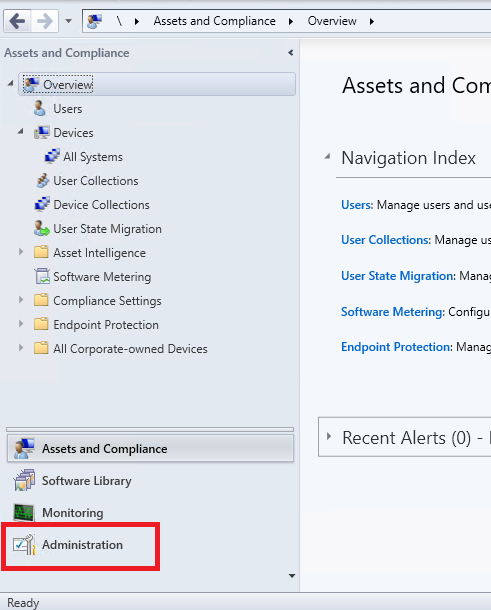
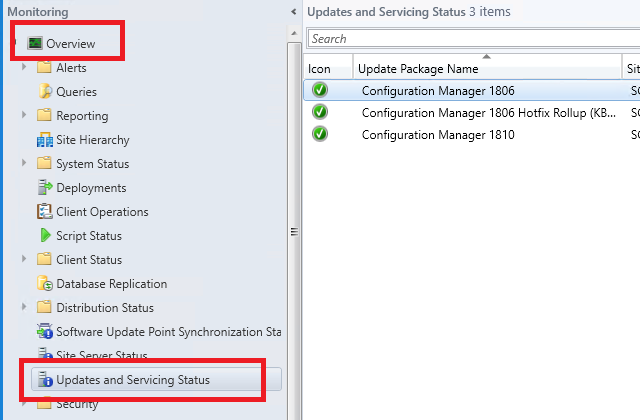
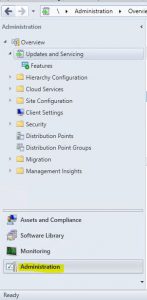
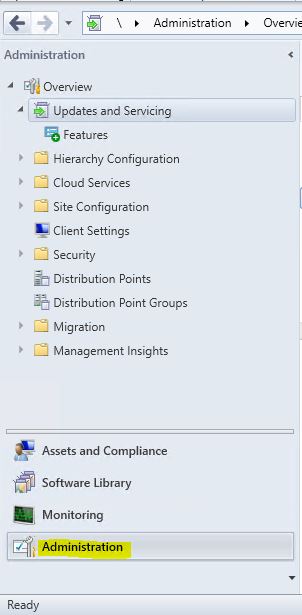
- Open your Configuration Manager Console and navigate to the Administration tab.
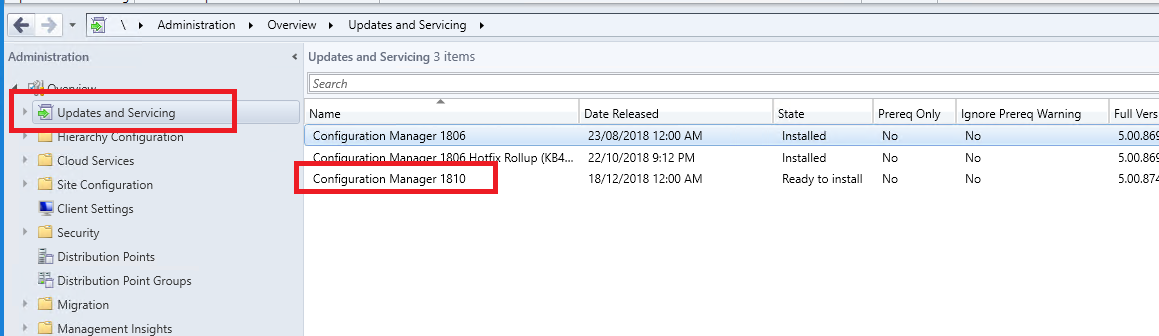
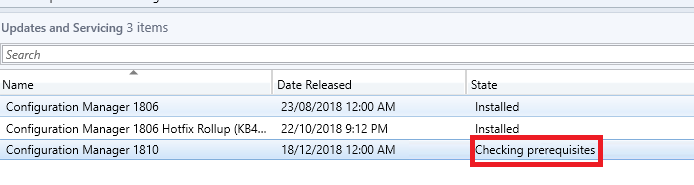
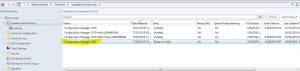
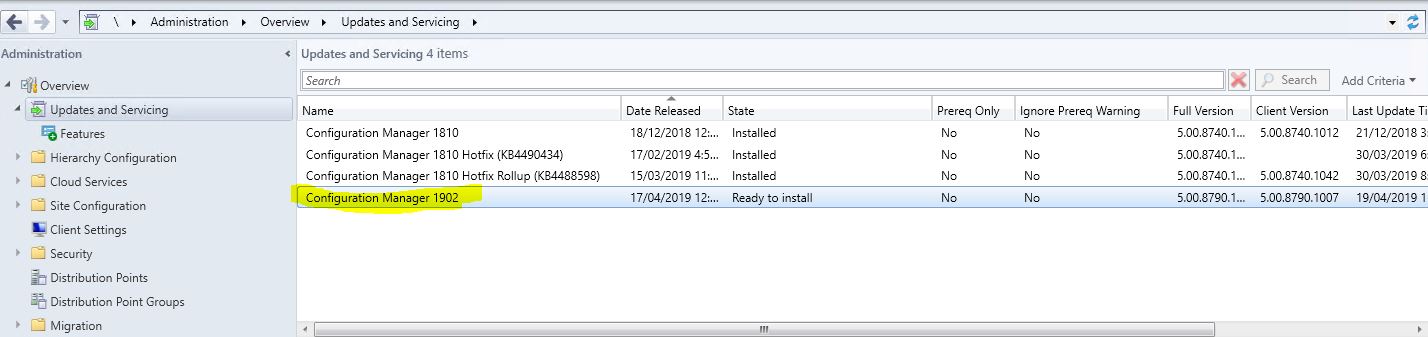
- Next we need to see if configuration manager has downloaded the SCCM 1902 update. Go click on Updates and Servicing and in the right side window, see if you have the update available.
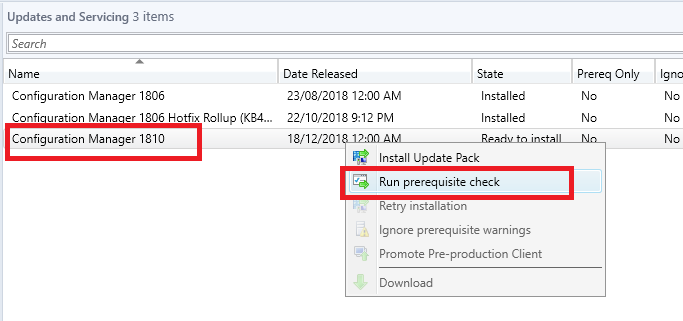
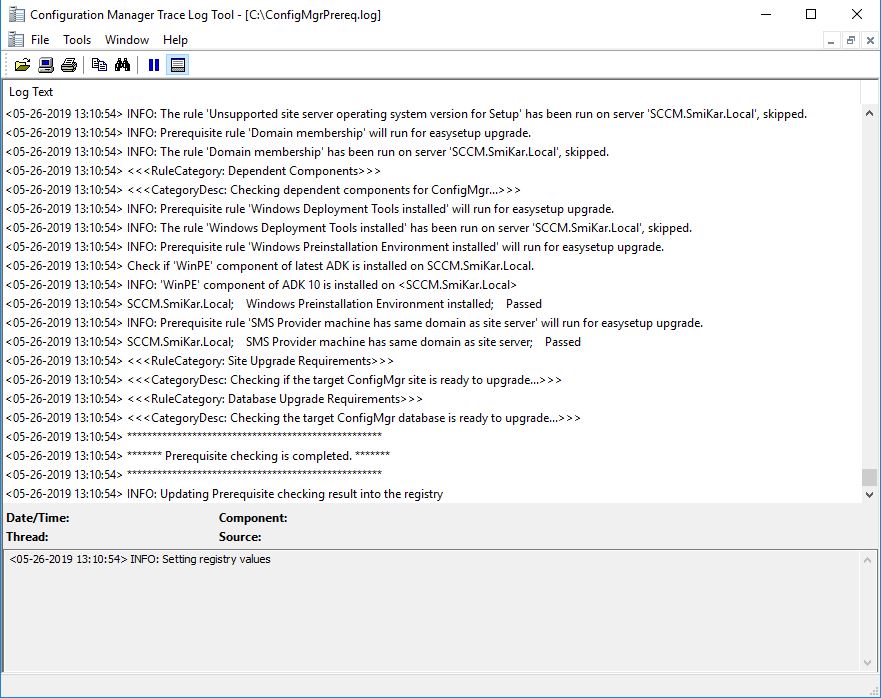
- Now we need to check the SCCM 1902 prerequisites are met before install this update. Right click the Configuration Manager 1902 update and choose Run Prerequisite Check.
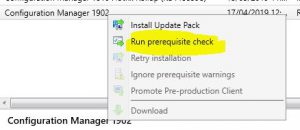
- The prerequisite check will run in the background. Keep refreshing your SCCM console to see the status of the check.

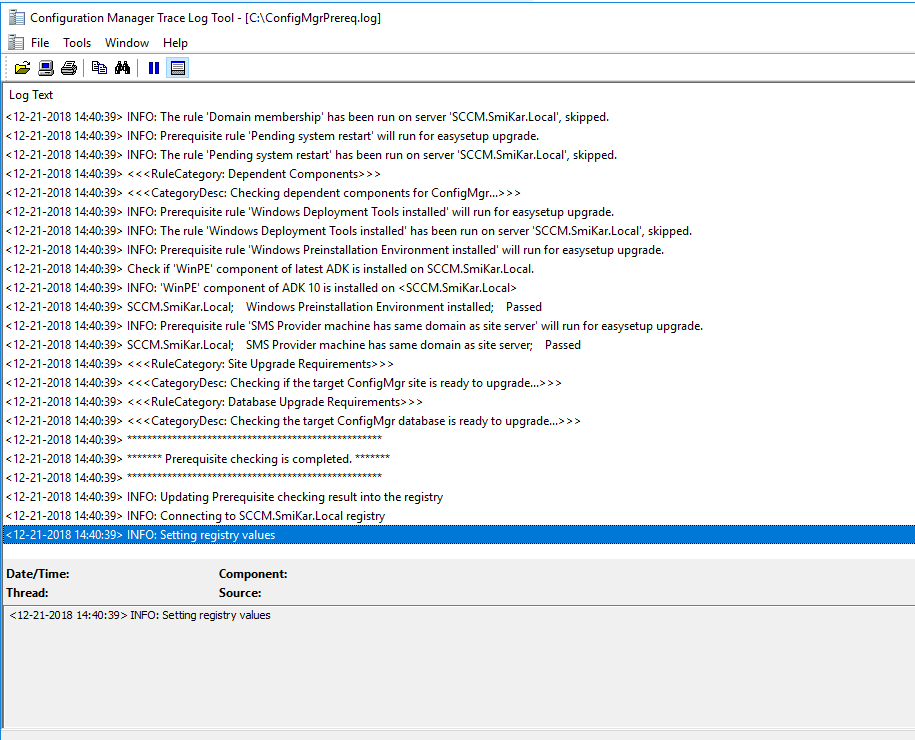
You can also check the ConfigMgrPrereq.log located in your SCCM Server’s C Drive for further details of the sccm 1902 prerequisite check.
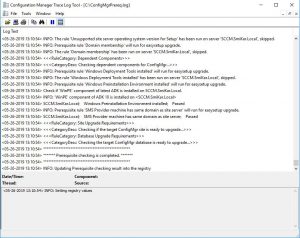
This may take some time (around ten minutes) so go grab a coffee or a cup of tea while you wait and hopefully when you come back and refresh your configuration manager console you see
Prerequisite Check Passed
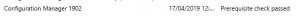
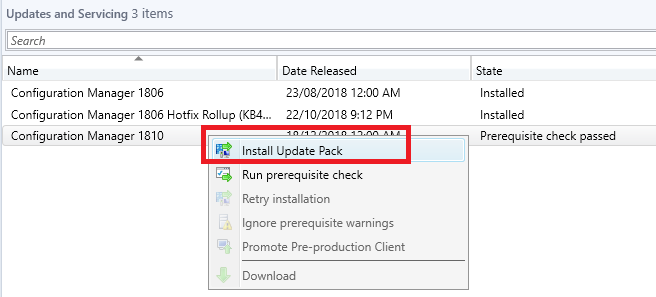
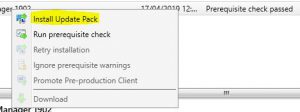
- Now on to the fun stuff, upgrade your configuration manager environment to SCCM 1902.
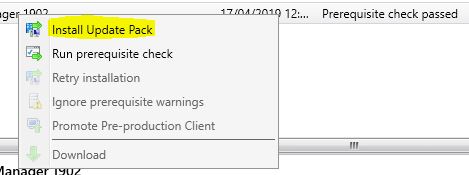
Right click the Configuration Manager 1902 update and choose Install Update Pack.
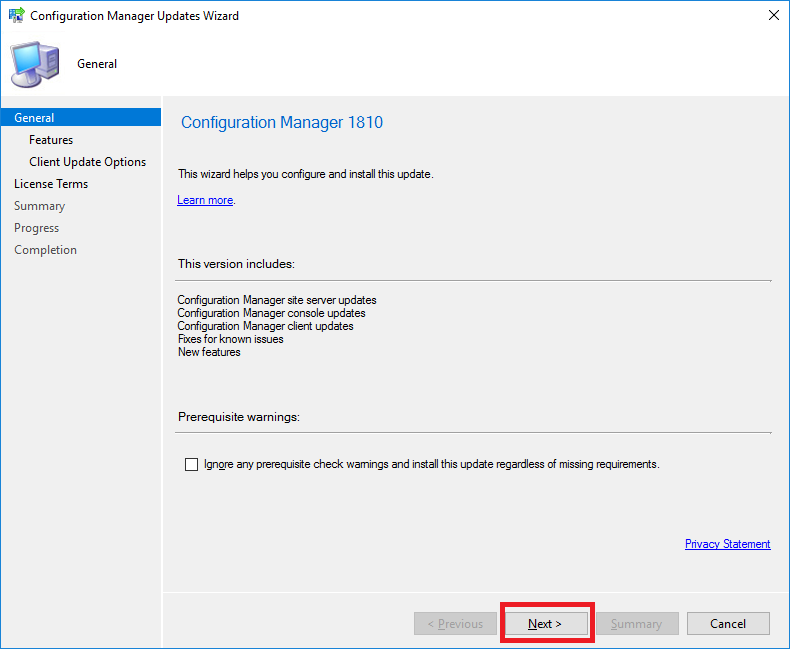
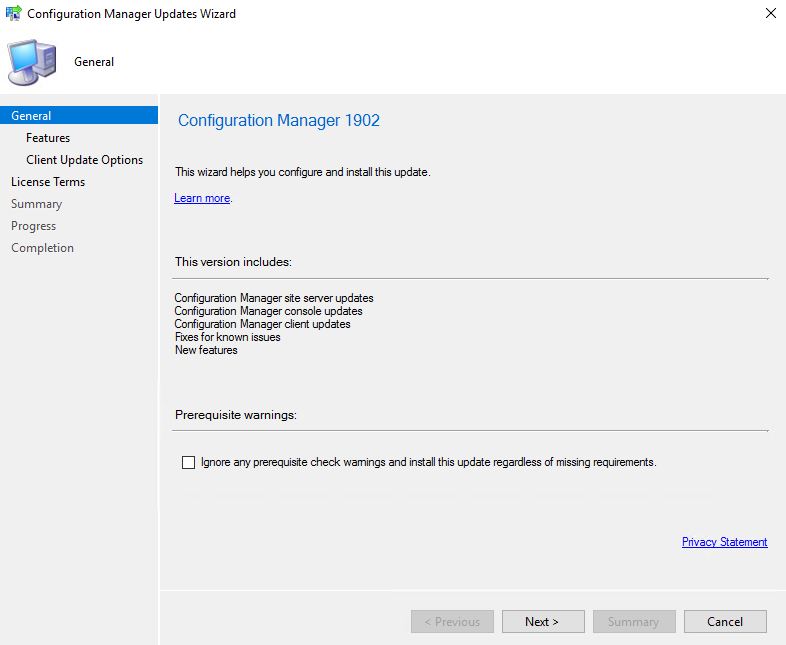
- The Configuration Manager Update Wizard now presents, ready for you to start the SCCM 1902 upgrade process. Click on Next to continue.
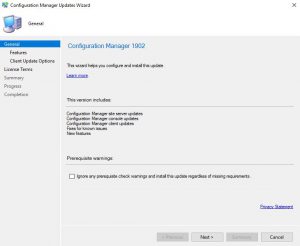
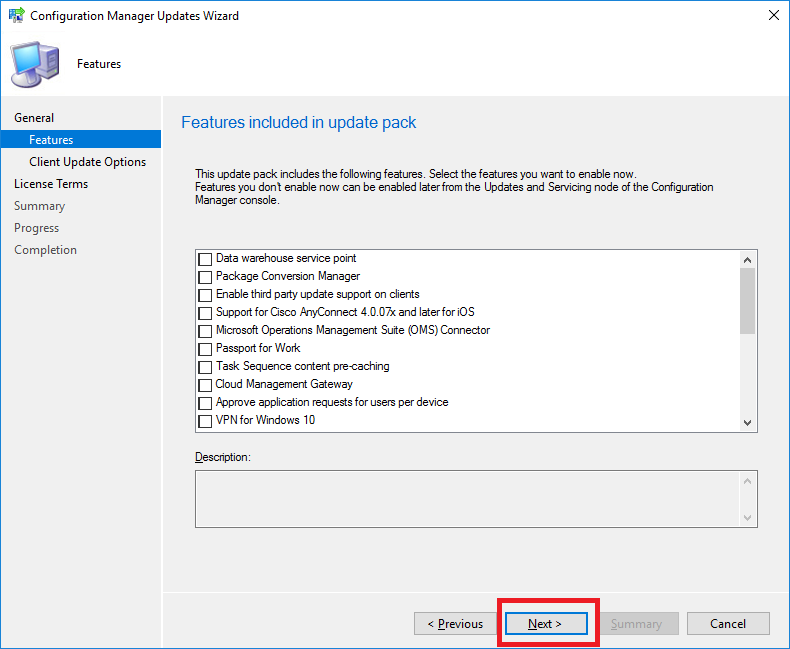
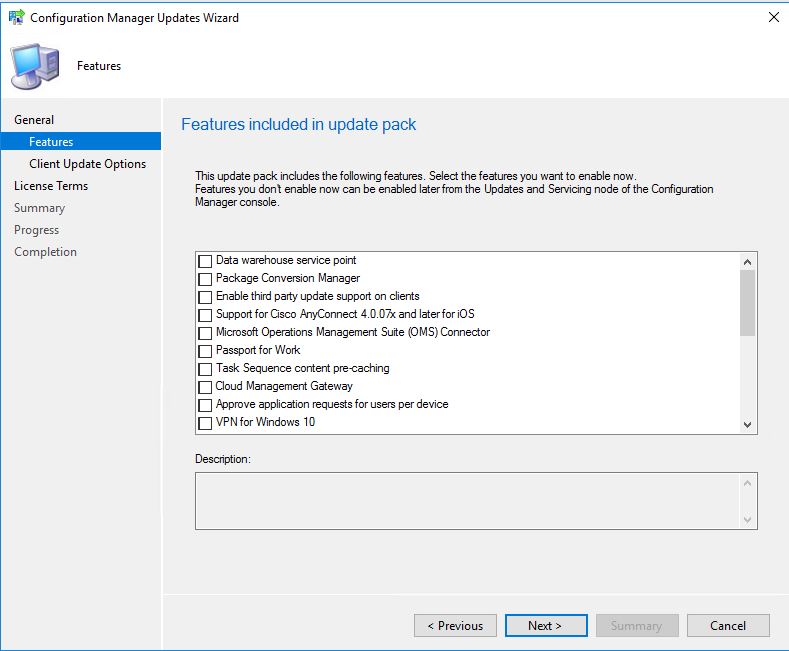
- We are now prompted with the features we wish to upgrade or install as part of this update. Carefully choose which features you need then click Next.
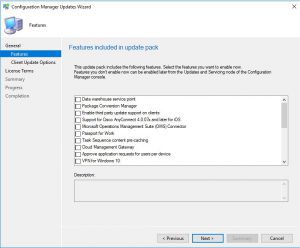
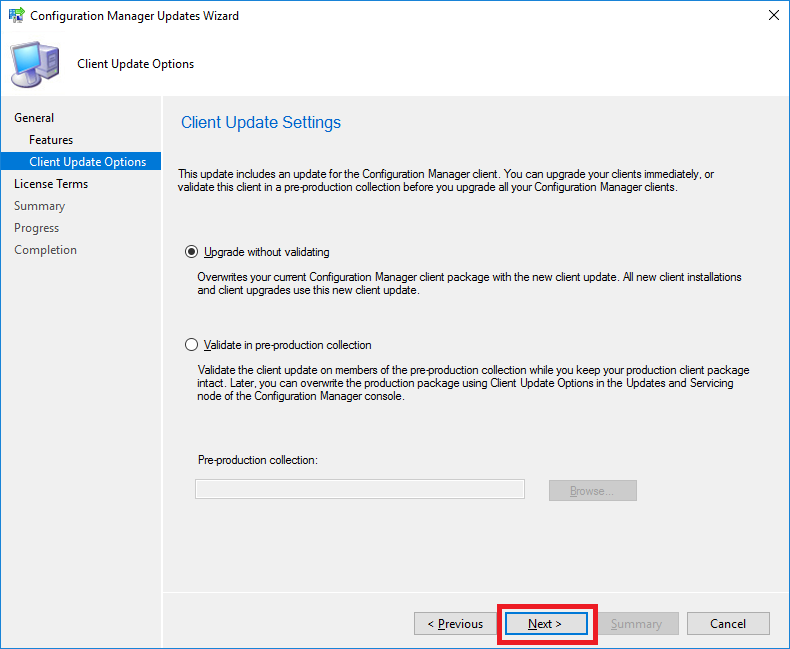
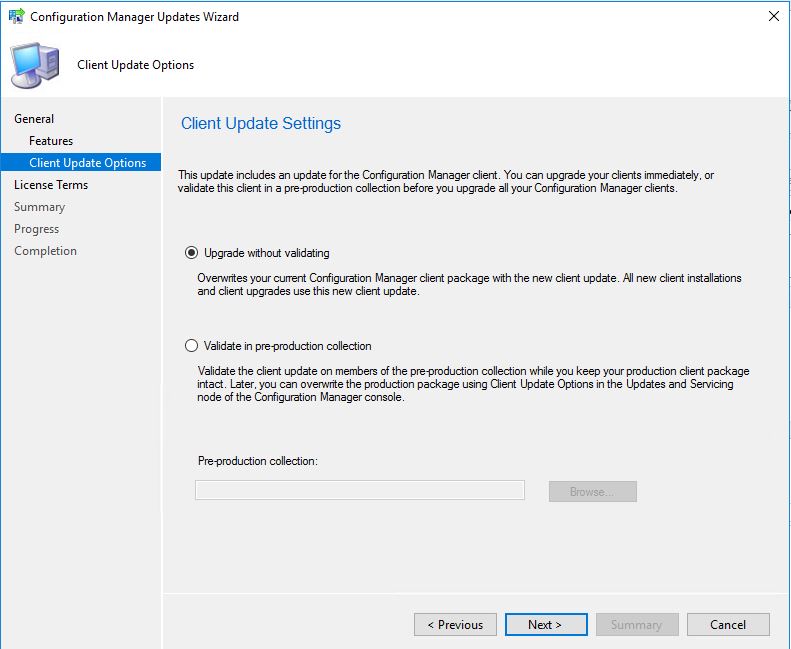
- If you have a preproduction collection to test the upgrade before deploying to your production collections, you can choose to do so on this screen. As this is one of our test labs, we wont go ahead with that and deploy this straight to production.
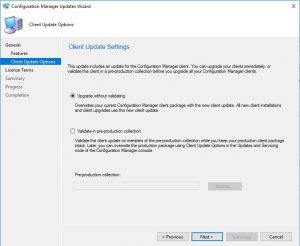
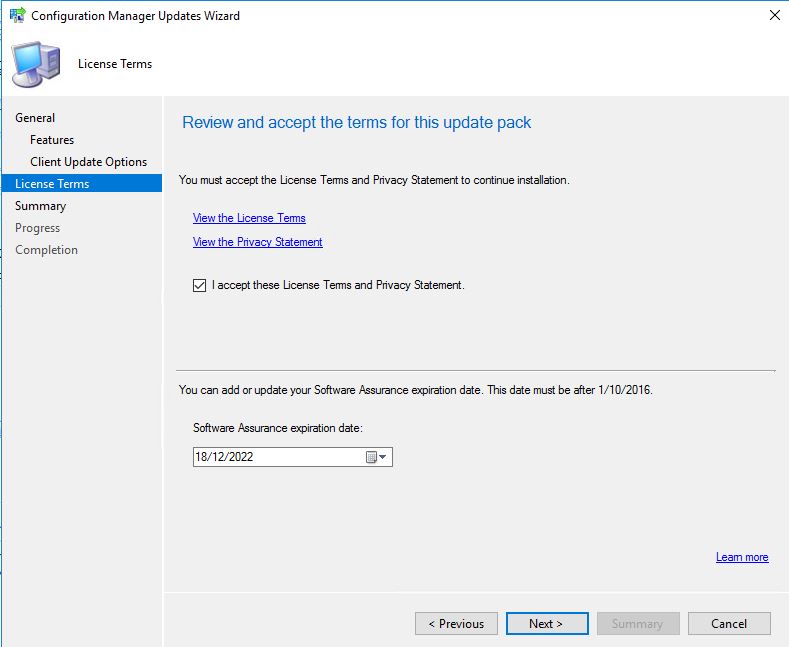
- You can review the license terms and conditions on this tab, make sure to check the checkbox to accept the terms of the license and then click Next.
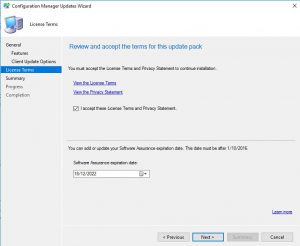
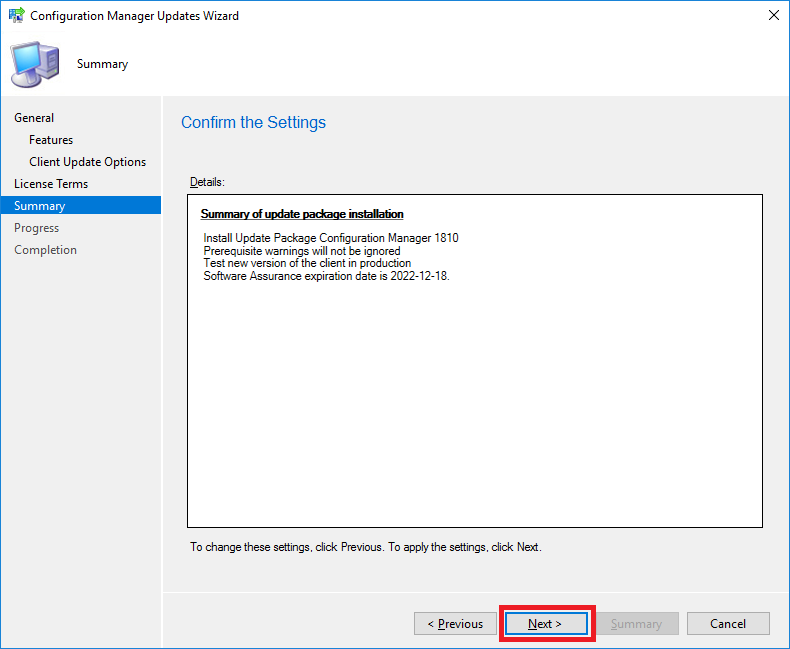
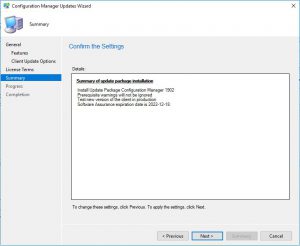
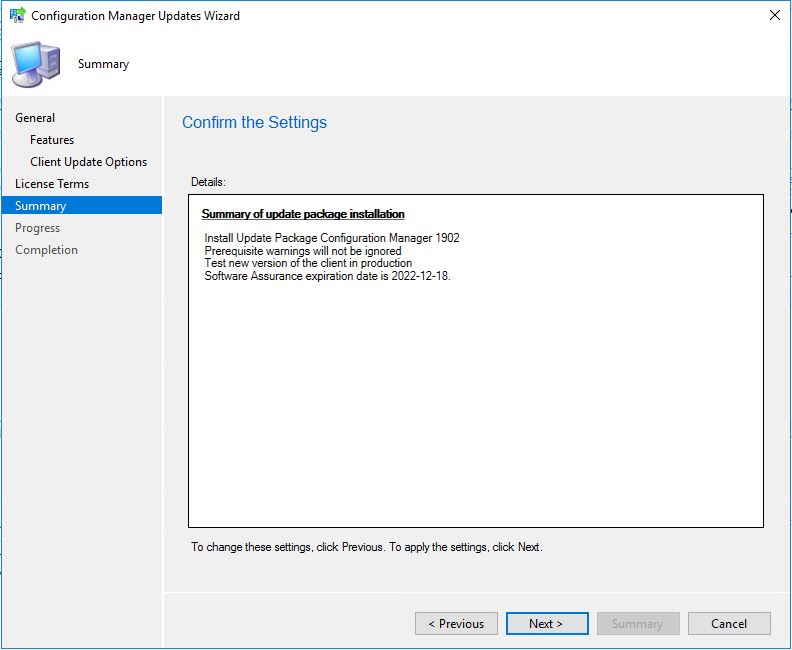
- Make sure on the Summary page that you have all the options you wish to upgrade or install displayed here, then click Next.
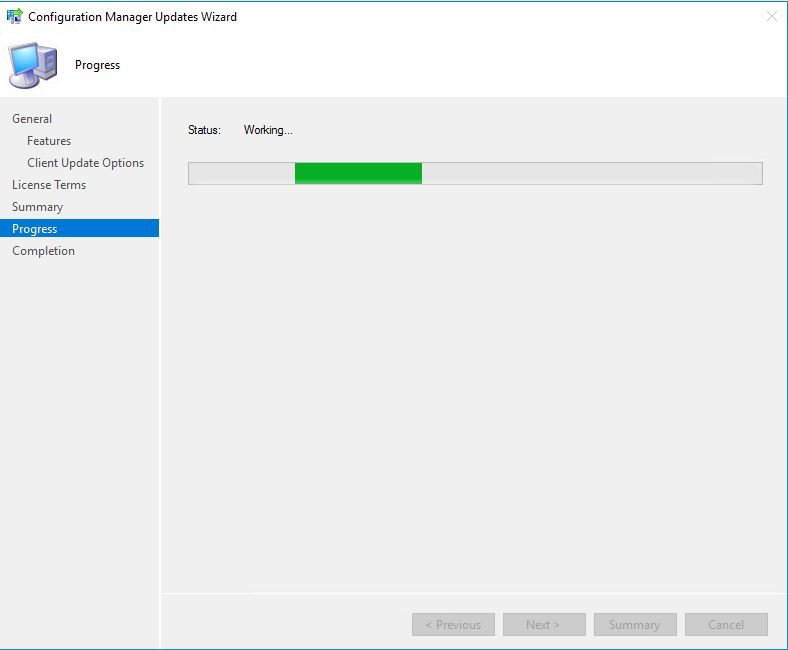
When you click next this will now start the upgrade process for SCCM.
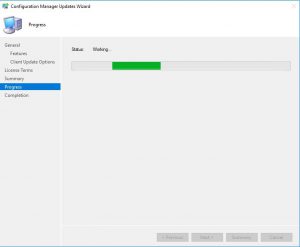
- Now the SCCM 1902 upgrade will start the update process.
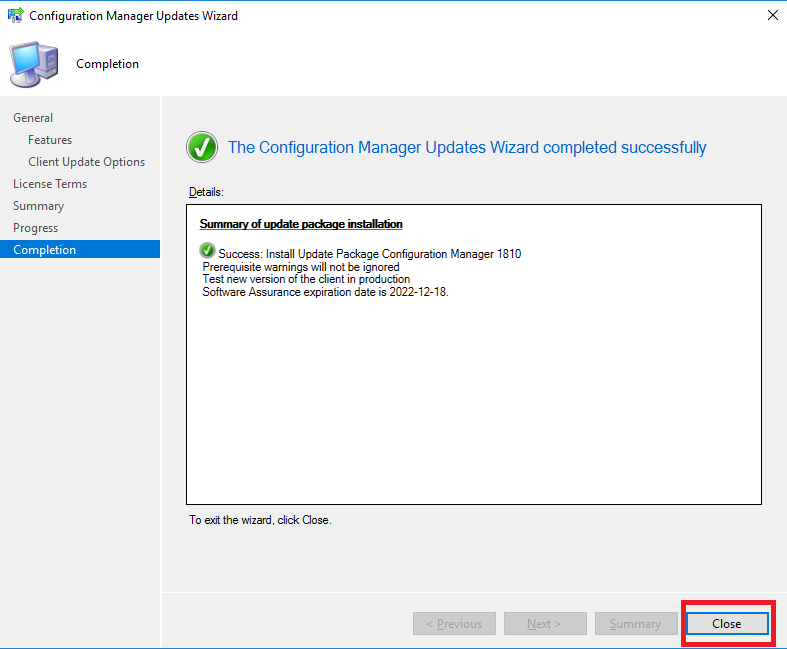
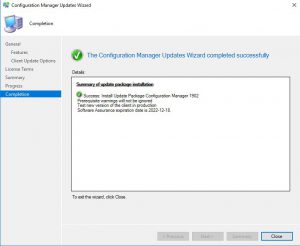
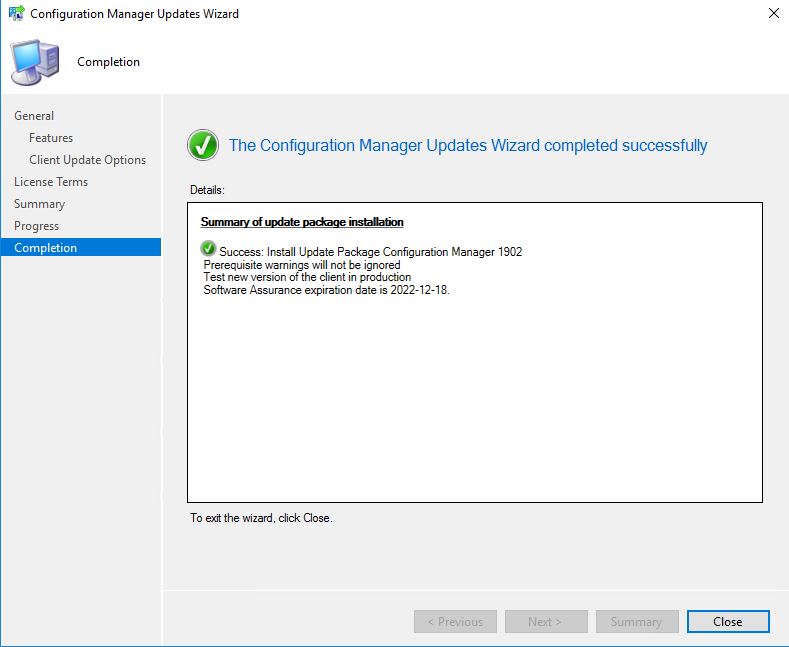
- The last screen is your completion screen, dont be fooled that it says completed, the update is still running and updating your SCCM infrastructure in the background.
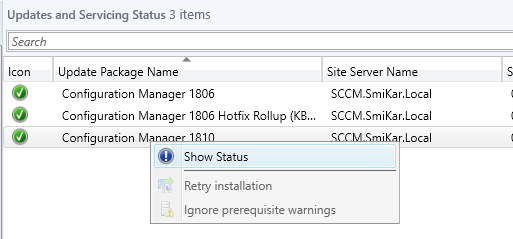
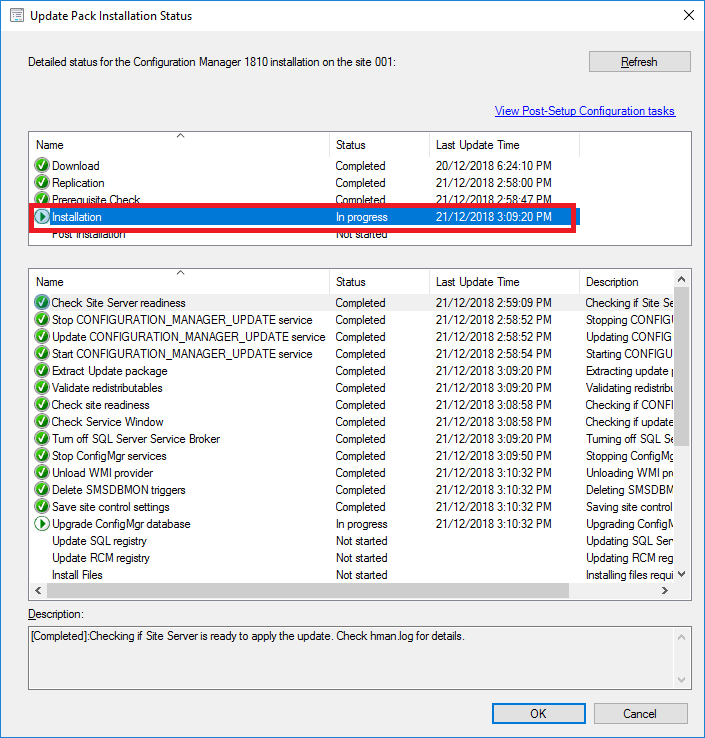
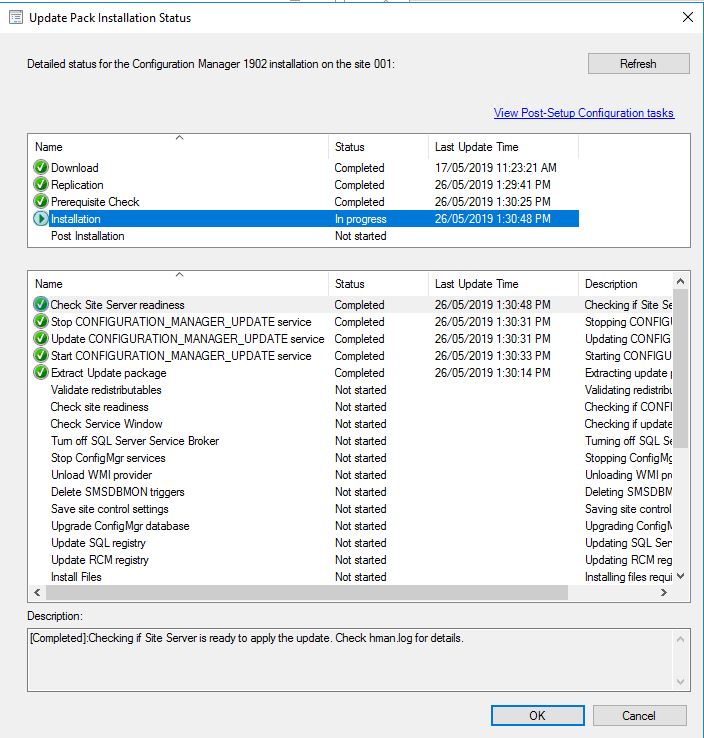
- To monitor the updates progress, go to the Monitoring tab, then Updates and Servicing Status. Choose the Configuration Manager 1902 update, then right click this then Show Status. From here, highlight Installation to watch the install status.
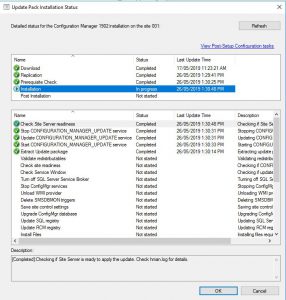
In the above picture you can see that our SCCM environment is still installing the update.
The update process may take some time, expect around 30 minutes. - Finally, after some time and the update process was successful, you should be able to see in the configuration manager console, that Configuration Manager 1902 has a state of Installed.

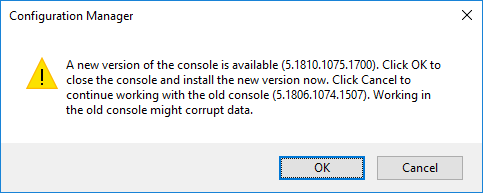
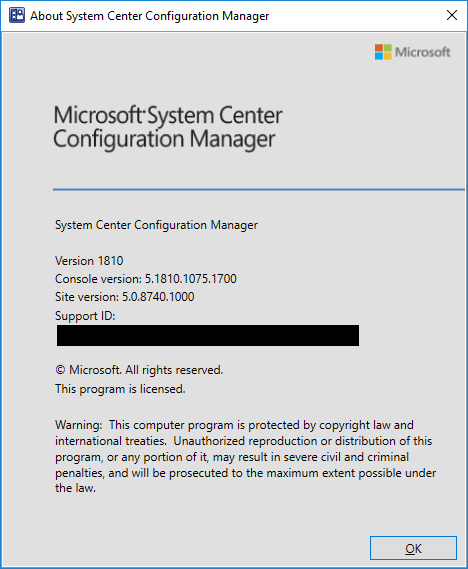
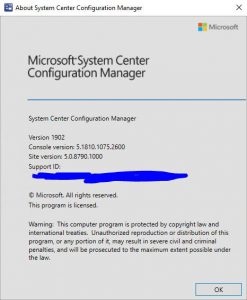
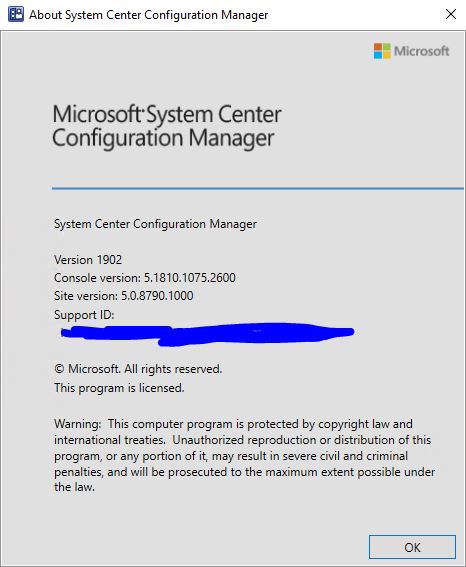
You can also click About Configuration Manager under the drop down arrow in the top left corner of the configuration manager console to see what version you are running. If everything was successful, you should see the version of your SCCM now showing 1902.

While you are here, dont forget to check out our software.
SnaPatch, which integrates with SCCM, VMware and HyperV to automate a snapshot then deploy patches to your virtual fleet.
SnapShot Master also integrates with VMware and HyperV and allows you to schedule snapshot creations then deletions.
Our Azure Management tools, that make your life easier to deploy, delete, shutdown and startup with orchestration of your Azure IAAS enviroment.
And finally, CARBON which replicates your Azure VMs back to your on-premise infrastructure with a simple few clicks.