
70-534 – Maintaining the Azure Cloud

Azure Overview
As explained in the previous post around the Azure Datacentres, Microsoft’s Azure offerings have to be reliable, have high performance and be incredibly resilient. Therefore maintaining the Azure Datacentres can be quite a complex procedure. Microsoft has to have a plan in place for the two possible scenarios of maintenance, planned and the unplanned. Planned maintenance happens on a schedule, while unplanned maintenance occurs in response to an unexpected event, normally due to a hardware failure.
Azure Planned Maintenance
Microsoft routinely schedule maintenance of their hosting hardware. Whether these are a firmware update or applying a security patch to the underlying hypervisor. While most of these will not effect the virtual machines you have running on this infrastructure, there are some circumstances which may cause your VMs to shutdown and restart. Obviously Microsoft providing a multi-tenanted environment, it would be near impossible to schedule the downtime of all their customers servers that would be effected by the maintenance, so hence this may occur to your VMs

Azure Availability Sets
So how do you avoid this and ensure your application keeps on going? Well Microsoft have an Service Level Agreement (SLA) in place only for multi instance VMs in the same logical group, which is called an availability set. When Microsoft performs maintenance, they ensure that not all the virtual machines within the same availability set will be restarted at the same time. So to give your applications the best chance, ensure that you have at least two virtual machines performing the same function (perhaps clustered for example) within the one availability set. Always remember that a single virtual machine will not have an SLA available and could be restarted at any time. During an Azure datacentre maintenance, the single instance VMs are brought down in parallel, then upgraded and restarted in no particular order. So if you have your applications on single instance Virtual Machines, they will naturally be unavailable during the maintenance window. Microsoft does send customers an email prior to any scheduled maintenance, detailing the date and time the outage is to be expected, but this is only for planned maintenance. Unplanned maintenance you will of course not be notified.
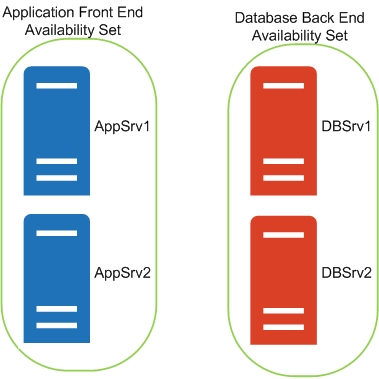
Azure Resilience
As shown in the example picture above, we have two Front End servers for the application within their own availability set, with the corresponding database servers also in their own one. AppSrv1 will be on a different host, and perhaps even rack to AppSrv2. Should the host running AppSrv1 have an issue and have the need to restart all the virtual machines running on that host, then this will not effect AppSrv2. Same thing goes for the database servers. It is best practice to also separate your application databases and other roles and have them in their own availability sets.
Where possible, always create multiple instances of your virtual machines and have them within the same availability set. If you do this you will then qualify for the Microsoft SLA.
Azure Update Domains
Azure Update Domains (sometimes these maybe called Upgrade Domains) are utilised for planned updates to the Azure Cloud service. The default number of Update domains is five with a maximum of twenty available to each availability set. Your virtual machines are spread across update domains to avoid outages to your applications and as Microsoft rolls out updates to their infrastructure, they will only ever update one update domain at any time. This will avoid unnecessary outages to your system
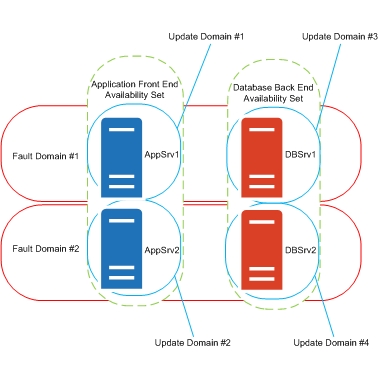
Azure Unplanned Maintenance
So what happens when there is unplanned maintenance I hear you ask? As I am sure you are quite aware, problems with hardware can be a regular occurrence at times. Failures with the network, server issues and even total rack failures can and do happen. Azure detects these failures automatically and will migrate your virtual machines to another host that is healthy.
Azure Fault Domains
Azure fault domains are a boundary between the infrastructure within the same datacentre to help prevent issues caused by unplanned outages. Multiple virtual machines that are deployed in the same availability set are also allocated to different fault domains. Fault Domains can be on separate racks, separate power supplies, different switches and sometimes even cooling systems. Fault Domains within Azure are assigned in a pattern, FD0, FD1, FD0, FD1 and so forth. All this helps alleviate any unplanned localised hardware failures that will interrupt services to your virtual machines. It is very unlikely that there will be issues with two or more fault domains, in fact it is more likely that there is a whole datacentre outage, which in this case you would need cross region replication.
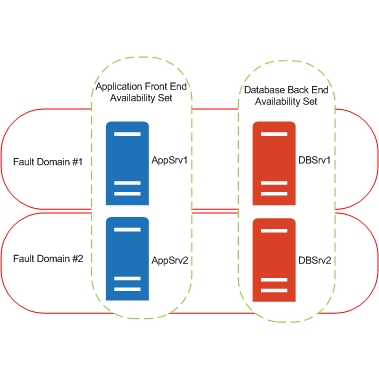
Azure Fault Domain Example
Now we have shown two fault domains with the availability sets detailed in the earlier diagram. You can see that AppSrv1 and DBSrv1 are in the same fault domain, and therefore more than likely on the same hardware or within the same rack. Should the rack or hardware have a failure, then AppSrv2 and DBSrv2 will not be effected by this outage and will continue delivering your applications.
VM Fault Domain
AppSrv1 0
AppSrv2 1
DBSrv1 0
DBSrv2 1
When you boot your servers within your availability set they will be allocated to a fault domain in an order, e.g. FD0, FD1, FD0, FD1, FD0, FD1 etc. The pattern of fault domain allocation never changes and will always follow this pattern.
So how does this work?
It is worth noting, that each availability set automatically creates two Fault Domains and is assigned to five Update Domains. For example, you build an availability set with six virtual machines. The first five are allocated to the five Fault Domains, and the sixth virtual machine is then added in to the first Fault Domain, with the first VM. In the worst case, VMs number one and six could be restarted at the same time if a maintenance event was to occur. As Update Domains are only ever restarted one at a time and that the restart order of the Update Domains isnt always sequential, these can be restarted in any order.
Cross Region Redundancy
Now, what happens in the unlikely event that a complete Azure Datacentre has an issue. Cross region redundancy is available within Azure which is basically a backup copy of your data in a secondary Azure datacentre (replication of your VMs to a second region). You can set up Cross Region Redundancy for your applications that require this level of service (thinking Tier 1 applications for the most part). You select the primary region to deliver your services from, choose a secondary region and Azure will take care of the replication. In the event of something catastrophic of the primary region, the system will automatically failover to the secondary region. The beauty of this service is that this happens automatically, there is no manual intervention required. Azure automatically takes care of the replication and the failover.
Service Throttling
As Microsoft’s Azure is a multi-tenant environment, with many many customers, how can Microsoft fairly monitor consumption? Service throttling will ensure consistent delivery of services to every customer they have according to the customers subscription limits. If throttling does ever occur, the experience that will be delivered will be degraded services. Azure bases this throttling on a few different criteria. From the amount of data stored, the number of transactions and system throughputs. You do always have the option to increase your limits should you ever reach them. As always, you should plan your architecture within Azure with performance in mind, but if the need arises you can scale up and scale out as needed.
FAQs
| Question | Answer |
|---|---|
What is Azure planned maintenance? |
Azure planned maintenance is when Microsoft schedules maintenance of their hosting hardware, which could include firmware updates or applying security patches to the underlying hypervisor. Some virtual machines may need to be shutdown and restarted during this process. |
What is Azure Availability Sets? |
Azure Availability Sets is a feature that allows customers to group virtual machines together in the same logical group to ensure that they are not all restarted at the same time during maintenance. Having multiple instances of virtual machines in the same availability set qualifies customers for the Microsoft SLA. |
What is Azure resilience? |
Azure resilience refers to the ability of a system to withstand and recover from hardware failures or other unexpected events. To ensure resilience, it is best practice to separate application databases and other roles, and to have them in their own availability sets. |
What are Azure Update Domains? |
Azure Update Domains are used for planned updates to the Azure Cloud service. Virtual machines are spread across update domains to avoid outages to applications, and Microsoft will only ever update one update domain at any time. |
What is Azure unplanned maintenance? |
Azure unplanned maintenance occurs in response to unexpected events such as hardware failures. Azure automatically detects these failures and migrates virtual machines to another healthy host. |
What are Azure Fault Domains? |
Azure Fault Domains are a boundary between infrastructure within the same datacenter to prevent issues caused by unplanned outages. Multiple virtual machines deployed in the same availability set are allocated to different fault domains, which can be on separate racks, power supplies, switches, or cooling systems. |
How do I ensure my applications are resilient in Azure? |
To ensure application resilience in Azure, it is recommended to group virtual machines in the same availability set, separate application databases and other roles, and have them in their own availability sets. |
How does Azure handle unplanned outages? |
Azure automatically detects unplanned outages and migrates virtual machines to another healthy host. |
How does Azure prevent outages during planned maintenance? |
Azure uses Azure Availability Sets and Azure Update Domains to prevent outages during planned maintenance. |
Well thats it for todays post. Ill continue with the Architecting Azure Solutions 70-534 study in a further post. Make sure you book mark this site for further updates.